 网络爬虫公司被谷歌起诉,被告反称谷歌才是“全球最大爬虫”
网络爬虫公司被谷歌起诉,被告反称谷歌才是“全球最大爬虫” 拖把
拖把据媒体The Verge报道,被谷歌起诉的SerpApi是一家网络内容抓取工具公司,或者更直接一点,叫网络爬虫公司。他们在上周五提交的驳回动议里反呛一嘴,称谷歌才是网络爬虫的始作俑者,是“全球最大的网络爬虫”。
众所周知,搜索引擎为什么能帮你搜到内容,靠的就是网络爬虫。搜索引擎的网络爬虫可以遍历开放的各个网络,从网站上爬取所有的信息并记录,这才能让你搜索到。它还会定时回访已经抓取过的网站,为的就是确保对网站数据的技术更新。
以上说的这些都是良性的行为,它其实也有恶意行为,比如某些爬虫程序可以无视网站访问频率限制,用极高的频率抓取数据,这就会导致网站服务器崩溃;比如某些爬虫程序不遵守君子协议,抓取了网站规定范围之外的隐私数据,侵犯了用户的利益等等。

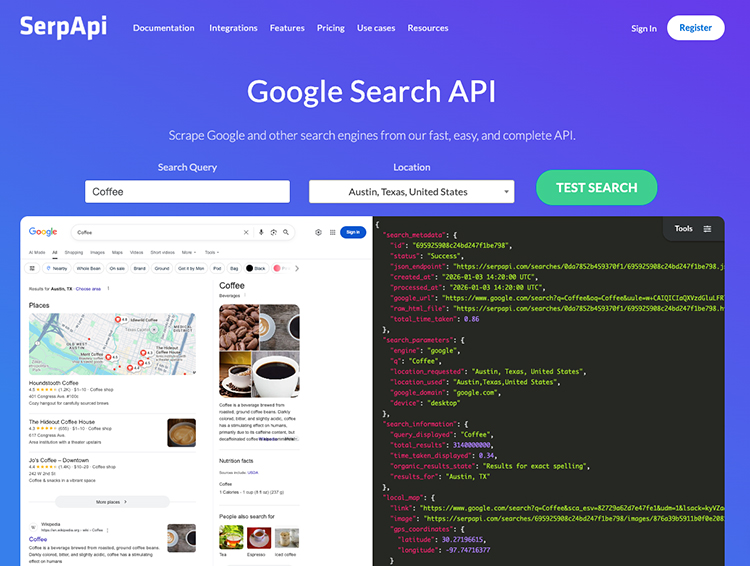
SerpApi的驳回动议书里称“谷歌才是全球最大的网络爬虫”
在谷歌诉SerpApi的案件中,谷歌指控的罪名是“以惊人的规模”抓取搜索结果,而且使用了“欺骗手段”访问并抓取谷歌的搜索结果,相当于用谷歌搜索的数据库来“炼丹”,谷歌称这违反了《版权法》,并且还指控SerpApi发现了绕开其反抓取功能SearchGuard的方法,对谷歌造成了损失。
在SerpApi的驳回动议中,他们表示只是在做“谷歌对其他所有人做的事情,只是规模小得多。”而且还说谷歌并没有“对其搜索结果主张所有权”,其从公共网站抓取的公开信息并不受版权保护,绕过SearchGuard的行为也没有违反《版权法》,因为这个功能只保护谷歌的业务,而不是用来保护版权内容。
SerpApi的态度也挺明确的,咱都是干这行的,你谷歌能爬得,我SerpApi就爬不得?你搁哪儿狂啥呢?只能说,这场诉讼纯属贼喊捉贼的行为,大家都是靠爬虫起家的,同行是最了解同行的,谷歌你也别想着高人一等了。















 沪公网安备 31010702005758号
沪公网安备 31010702005758号
发表评论注册|登录